· Andreas Schwarz · Fachartikel · 9 min read
Wissen und Verfügbarkeit: Vom Suchen zum Finden
Wissen verfügbar machen senkt operative Risiken, beschleunigt Onboarding und schafft die Basis für belastbare Prozessautomatisierung.

Teaser
Wissen ist nur dann wertvoll, wenn es dort verfügbar ist, wo Entscheidungen fallen und Arbeit passiert. Dieser Artikel zeigt, wie Sie Wissen aus E-Mails, Laufwerken und Tools in verlässliche Antworten verwandeln. Sie erfahren, warum das für Prozessautomatisierung, bessere Entscheidungen und schnelleres Onboarding entscheidend ist. Und Sie bekommen einen einfachen, umsetzbaren Fahrplan für einen belastbaren Pilot in wenigen Wochen - ohne Tool-Debatte, mit klaren Schritten und messbaren Ergebnissen.
Wissen und Verfügbarkeit: Vom Suchen zum Finden
Wissen ist der Stoff, aus dem Entscheidungen entstehen. Doch in vielen Unternehmen liegt es unsichtbar in Postfächern, Notizbüchern, Abteilungsablagen oder verteilt über Tools. Die Folge sind Verzögerungen, Doppelarbeit und Risiken. Wenn Informationen fehlen oder veraltet sind, geraten Projekte ins Stocken, das Onboarding dauert länger, und die gewünschte Prozessautomatisierung bleibt auf der Strecke. Dieser Beitrag beschreibt, wie Sie Wissen verfügbar machen, statt es nur zu verwalten. Er zeigt die typischen Problembilder, ordnet Ursachen ein und skizziert einen pragmatischen Weg zum Pilot.
Die Perspektive ist bewusst operativ. Entscheidend ist, wie Wissen dorthin gelangt, wo es gebraucht wird: in operative Prozesse, in Service-Tickets, in Projektentscheidungen. Dabei helfen semantische Suche, RAG und Governance, aber ebenso klare Verantwortlichkeiten und eine schlanke Datenstrategie. Es geht nicht um das nächste Tool, sondern um einen lernfähigen Zugang zu Wissen - integriert in Arbeit, sicher und auditierbar.
Zentraler Punkt: Wissen aktivieren, nicht nur ablegen. Relevante Antworten im Arbeitsfluss schlagen Ordnerbäume, Suchroutinen und Zufallsfunde.
Das Problem hinter Wissen und Verfügbarkeit
Viele Unternehmen kennen das Bild: Unsichtbares, personengebundenes Wissen, verteilt über E-Mail, SharePoint, Laufwerke und Fachtools. Teams suchen in alten Ordnern, fragen Kolleginnen an, durchsuchen Tickets oder warten auf Rückmeldungen. Entscheidungen basieren dann leicht auf veralteten Versionen, was Risiken für Qualität, Termine und Compliance erzeugt. Die Kosten sind selten sichtbar, aber spürbar: Verzögerte Projektstarts, zähes Onboarding, Nacharbeiten in Audits und Frust im Tagesgeschäft.
Die Suche nach Informationen frisst Zeit und Energie. Schnell kommen hier 1-2 Stunden Suchzeit pro Mitarbeiter pro Tag zusammen. Werden Inhalte nicht gefunden, entsteht Doppelarbeit oder es werden suboptimale Entscheidungen getroffen. Dazu kommt Unsicherheit: Ist dieses Dokument aktuell? Darf ich die Information nutzen? Ohne eindeutige Quellenlage und klare Berechtigungen steigt das Risiko, Entscheidungen auf unsichere oder veraltete Angaben zu stützen.
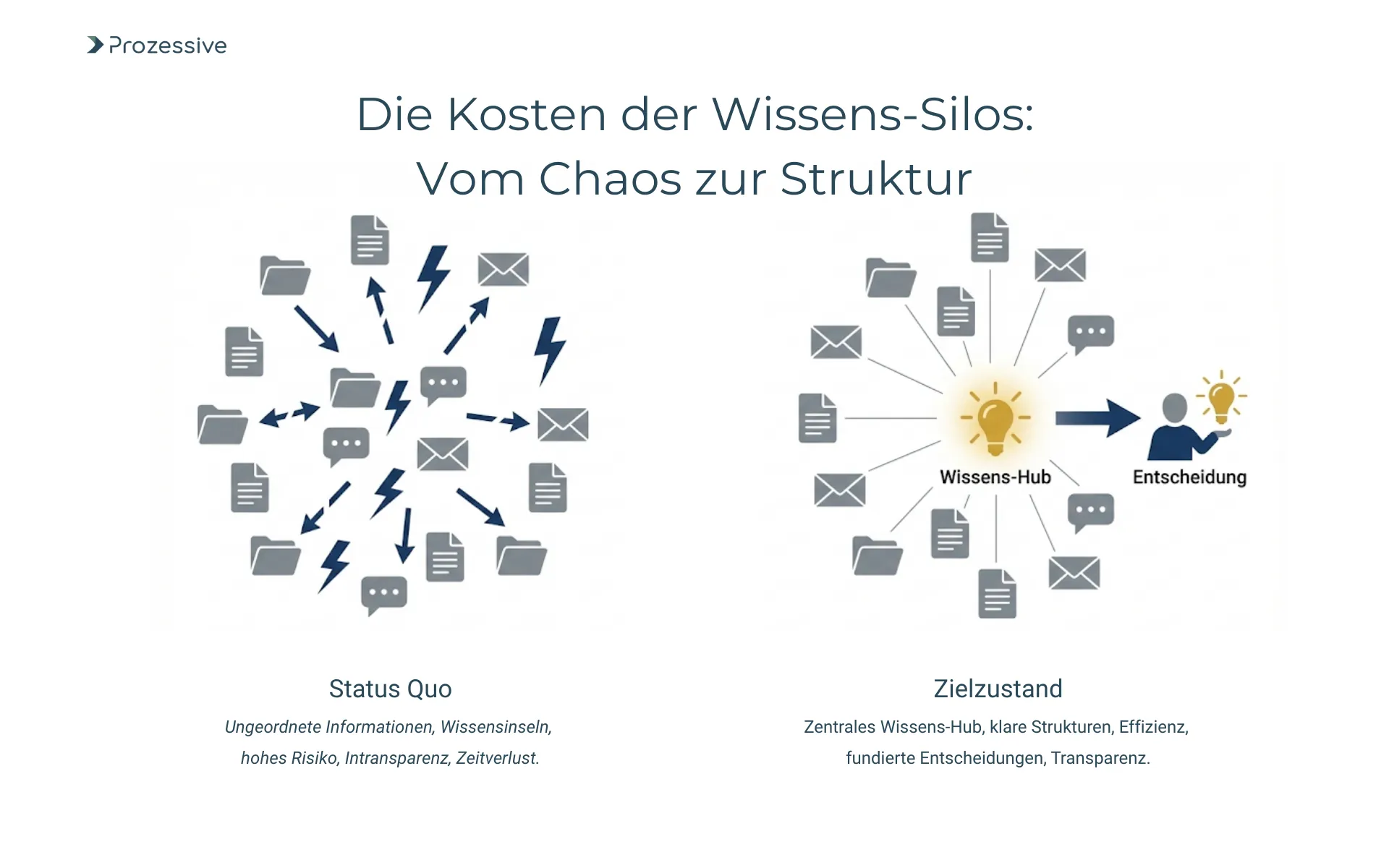
Für Prozessautomatisierung ist die Lage noch kritischer. Automatisierte Abläufe benötigen verlässliche, auffindbare, maschinenlesbare Informationen. Wenn Richtlinien, Prozessbeschreibungen oder Produktdaten in Silos liegen, bleiben Automatisierungen brüchig. Die Folge sind manuelle Workarounds, Ausnahmebehandlungen und ein ständiges Nachpflegen. Das bremst Skalierung, erhöht den Wartungsaufwand und senkt die Akzeptanz gegenüber weiterer Digitalisierung und Automatisierung.
Beispiele aus der Praxis
Das Thema wird greifbar, wenn man typische Situationen betrachtet. Nachfolgend Fälle, die sich in vielen Organisationen wiederfinden. Sie dienen der Einordnung, ersetzen aber keine Analyse.
- Unternehmensrichtlinien liegen in mehreren Versionen auf Laufwerken, im Intranet und in E-Mail-Anhängen; niemand ist sicher, welche gültig ist.
- Ein zentraler Experte geht in Rente; sein Know-how zu Anlagenparametern und Sonderfällen ist nur in persönlichen Notizen dokumentiert.
- Projektteams erstellen ähnliche Auswertungen mehrfach, weil sie Vorlagen und Ergebnisse anderer Teams nicht finden.
- Das Onboarding neuer Mitarbeitender zieht sich, da Checklisten, Rollenprofile und Fachbegriffe nirgends konsistent erklärt sind.
- Kundenservice braucht lange für Antworten, da Lösungen in Tickets, Wikis und Chatverläufen verstreut sind.
- Audit-Anfragen verursachen Ad-hoc-Recherche in Archiven, weil keine nachvollziehbaren Quellenketten aufgebaut sind.
- In der Produktion gehen bei Schichtwechseln Hinweise auf Abweichungen und Workarounds verloren; Eskalationen häufen sich.
- IT-Security erhält wiederkehrende Anfragen zu Standards und Prozessen, da eine verlässliche, durchsuchbare FAQ fehlt.
Diese Beispiele zeigen, wie Abhängigkeiten von Einzelpersonen und verteilte Informationen zu Reibungsverlusten führen. Die Konsequenz ist mehr als Zeitverlust: Es leidet die Qualität von Entscheidungen, und strukturelle Risiken - etwa in Compliance und Qualitätssicherung - wachsen. Daraus erwächst Handlungsdruck, der sich in einem Pilotprojekt gezielt adressieren lässt, bevor großflächige Veränderungen geplant werden.
Ursachen und Muster der Siloisierung
Hinter den Symptomen steht selten böser Wille, sondern gewachsene Landschaften. Fehlt eine Informationsarchitektur, entstehen Ablagen nach persönlicher Logik. Ohne einheitliche Metadaten und Taxonomien gibt es keine klare Auffindbarkeit. Dokumenttitel, Dateinamen und Ordnerstrukturen tragen dann Wissenslast, die sie nicht schultern können. Unterschiedliche Versionen entstehen kleinräumig, werden per E-Mail geteilt und leben als Schattenkopien weiter. Versionen werden verwechselt, Aktualisierungen erreichen nicht alle.
Ein zweiter Faktor ist Tool-Fragmentierung. Wenn Fachbereiche eigene Lösungen einführen, fragmentiert nicht nur die Ablage, sondern auch die Zugriffslogik. Informationen liegen in Project-Tools, Wikis, Ticketingsystemen und CRM - oft ohne gemeinsame Suche, ohne konsistente Berechtigungen und ohne einheitliche Verantwortlichkeit. Die Folge sind Silos, in denen ähnliche Inhalte mehrfach gepflegt werden. Das erhöht Pflegeaufwand und senkt Verlässlichkeit.
Drittens fehlt häufig eine klare Ownership. Wer ist verantwortlich für Gültigkeit, Metadaten, Berechtigungen, Lebenszyklen? Ohne Rollen für Content Owner, Reviewer und Datenverantwortliche veralten Inhalte schnell. Hinzu kommen fragmentierte Berechtigungen: Ein Team sieht, was es erstellt, aber nicht, was benachbarte Teams bereits gelöst haben. So entsteht Doppelarbeit - ein direkter Produktivitätsverlust, der zudem jede weitergehende Integration oder Automatisierung erschwert.
Lösungsansätze
Der Leitgedanke lautet: Wissen aktivieren statt nur verwalten. Das bedeutet, Informationen dort bereitzustellen, wo Arbeit passiert - kontextbezogen, berechtigungsgeprüft, als Antwort statt als Linkliste. Dazu braucht es eine schlanke Informationsarchitektur, saubere Metadaten, eine semantische Suche und - wo sinnvoll - KI-gestützte Verfahren. Wichtig ist, nicht in Tools zu denken, sondern in Prinzipien: klare Struktur, greifbare Rollen, nachvollziehbare Quellen, messbarer Nutzen.
Zentral ist die Einführung einer semantischen Suche, die natürliche Sprache versteht, Tippfehler toleriert, Synonyme erkennt und Inhalte über Tools hinweg auffindbar macht. Ergänzend lohnt sich Retrieval-Augmented Generation: Dabei werden kontextrelevante Dokumentpassagen gefunden und mit einem Sprachmodell in eine verständliche Antwort überführt. So entstehen geprüfte, nachvollziehbare Antworten - mit Quellenpassagen, die intern sichtbar sind. Das senkt Suchzeiten und erhöht die Qualität von Entscheidungen.
Die Rolle von Large Language Models wird dabei oft missverstanden. LLMs besitzen allgemeines Sprach- und Weltwissen, aber sie kennen Ihr internes Wissen nicht. Ohne Retrieval greifen sie auf Muster zurück - hilfreich für Formulierungen, riskant für Inhalte. Mit RAG werden nur berechtigte, interne Informationen herangezogen. Das ist die Basis für Sicherheit, Nachvollziehbarkeit und Skalierbarkeit im Einsatz von Künstlicher Intelligenz in Prozessen.
Parallel zur Technik gehören Governance, Sicherheit und Veränderungsarbeit dazu. Wer darf was sehen, wie wird protokolliert, wie bleibt das System aktuell? Zugriff nach Least Privilege, Datenschutzprüfung, Logging und klare Verantwortlichkeiten bilden den Rahmen. Genauso wichtig ist Befähigung: Teams benötigen kurze Trainings, Leitlinien für gute Fragen, und Feedbackkanäle, um Ergebnisse zu verbessern. So entsteht kontinuierliche Optimierung statt Einmalprojekt.
Retrieval-Augmented Generation (RAG) kurz erklärt
RAG verbindet zwei Schritte: Retrieval findet zu einer Frage die relevantesten Textpassagen aus internen Quellen, unter Beachtung von Berechtigungen. Generation fasst diese Passagen mit einem Sprachmodell in eine präzise Antwort zusammen. Die Antwort enthält interne Nachweise, die im Unternehmen einsehbar sind. So wird das Sprachmodell nicht zur Quelle, sondern zum Formulierungshilfsmittel. Der inhaltliche Beleg bleibt im eigenen Datenbestand, was Qualität, Vertrauen und Auditierbarkeit stärkt.
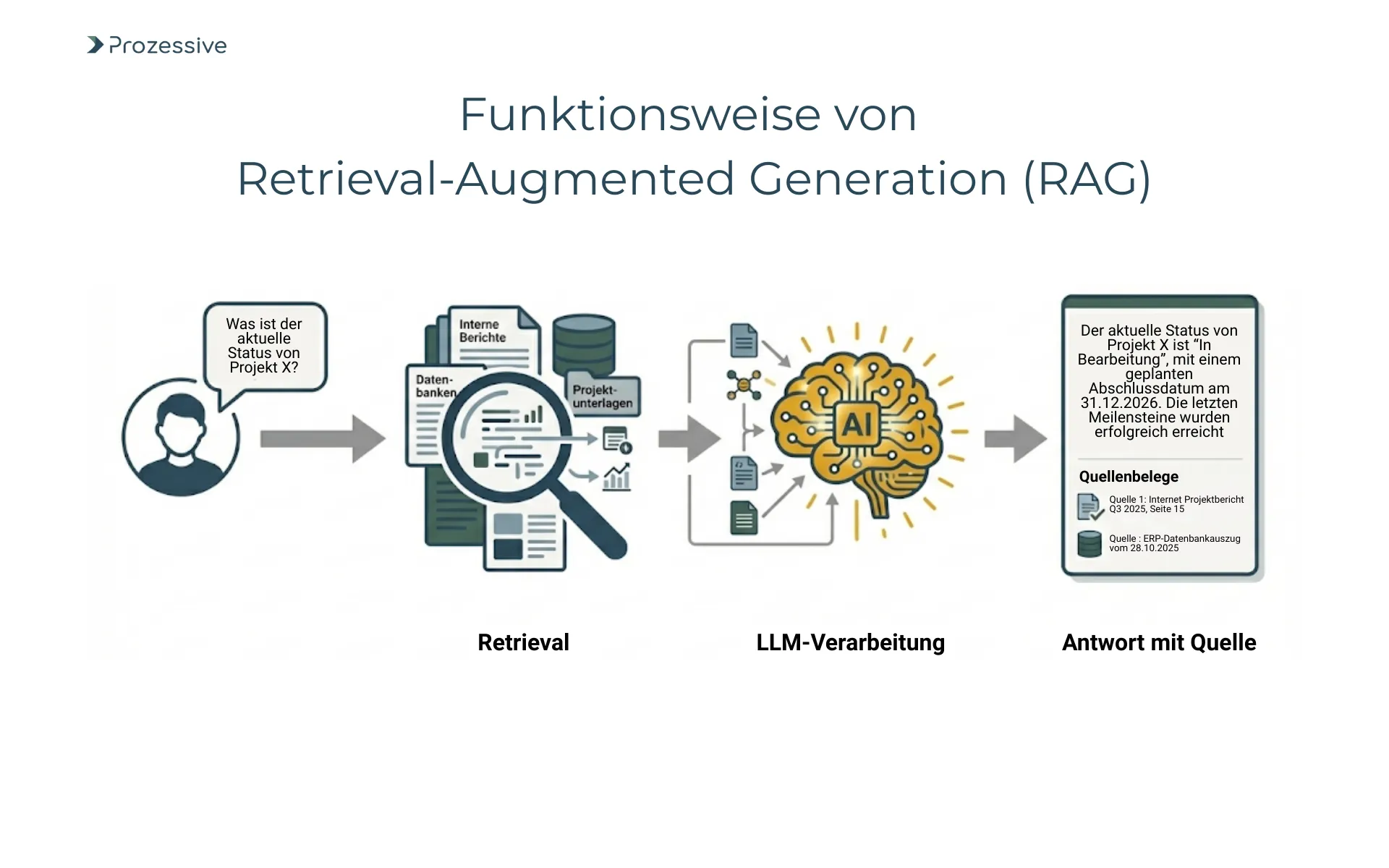
Large Language Models (LLM) im Kontext von Unternehmenswissen
LLMs beherrschen Sprache und Muster, aber ohne Anbindung an Ihre Inhalte liefern sie nur allgemeines Wissen. Für Unternehmensfragen braucht es deshalb gesicherten Kontext aus Ihren Daten. LLM plus RAG bedeutet: Antworten entstehen aus internen, berechtigten Quellen und bleiben überprüfbar. Ohne RAG steigt das Halluzinationsrisiko. Mit RAG wird das LLM zum Antwort-Assistenten im Arbeitsfluss - etwa in Ticketing, Intranet oder CRM - statt zu einer eigenständigen Wissensquelle.
Quickstart für Entscheider - in wenigen Wochen zum belastbaren Pilot
Ein funktionierender Pilot ist die schnellste Art, Nutzen und Risiken zu bewerten. Ziel ist eine verlässliche, kleine Lösung, die echte Arbeit erleichtert. Nachfolgend ein Fahrplan, der sich in 6-8 Wochen umsetzen lässt, je nach Datensituation.
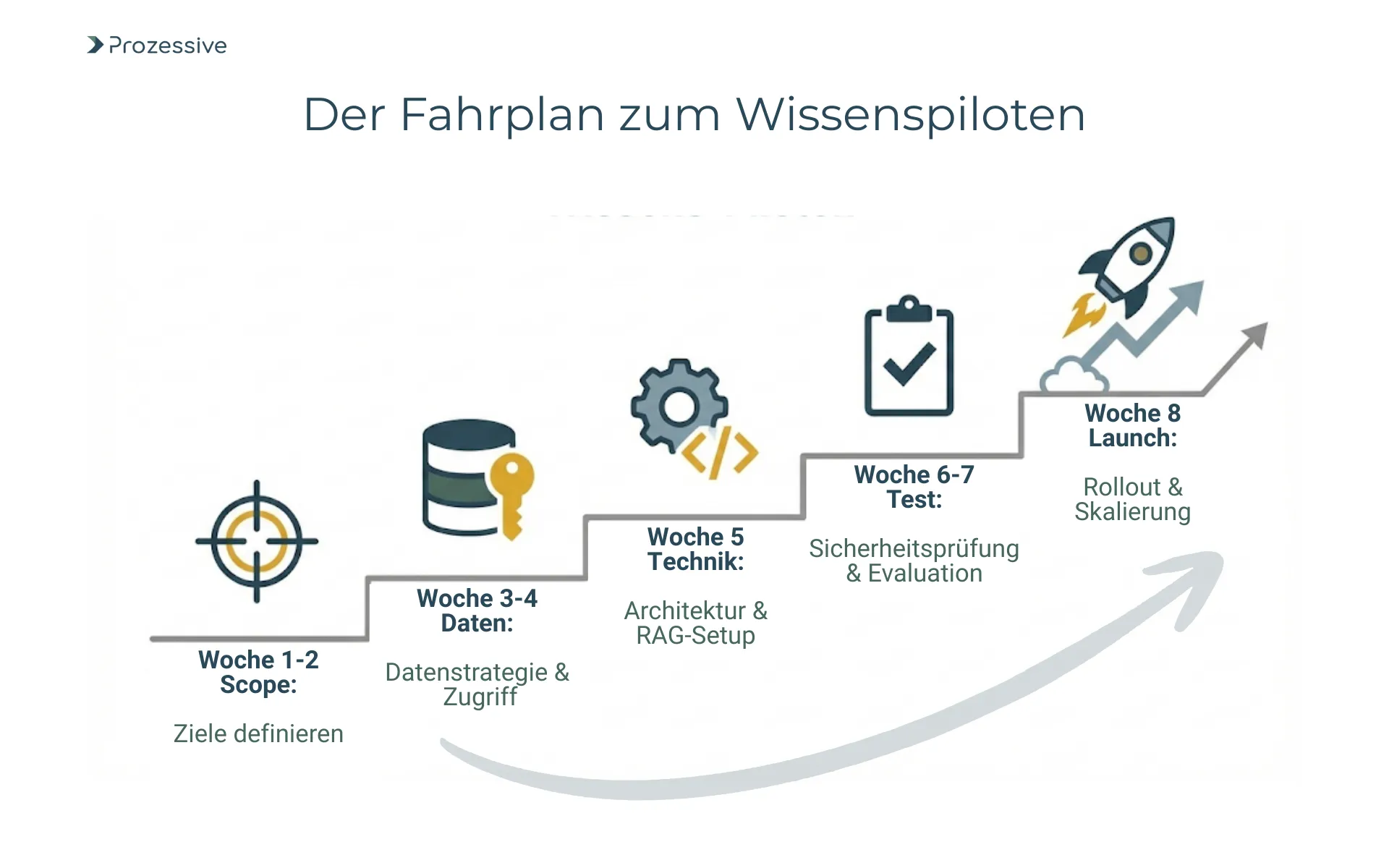
- Problemfeld und Ziel-KPIs definieren (z. B. Suchzeitreduktion, Erstlösungsquote), Scope klar begrenzen.
- 1-2 priorisierte Use Cases wählen, etwa Richtlinienwissen im Service oder Projektvorlagen im PMO.
- Datenstrategie light: Quellen inventarisieren, Formate und Berechtigungen klären und Betriebsgeheimnisse kennzeichnen.
- Minimale Architektur: Connectoren, Vektor-Index, semantische Suche, RAG, rollenbasierte Zugriffskontrollen.
- Sicherheits- und Datenschutzprüfung durchführen, inkl. Protokollierung und Least Privilege.
- Evaluationsdatenset und Messplan definieren (Antwortqualität, Zeitersparnis, Akzeptanz); Referenzdaten vorab erheben.
- Pilot-Rollout für definierte Nutzergruppe, kurzes Training und klare Feedbackkanäle.
- Iteration im 2-Wochen-Takt: Relevanz-Feedback, Korpuspflege, Prompt- und Ranking-Feinjustierung.
- Skalierungs- und Betriebsmodell ausarbeiten: Monitoring, SLAs, Ownership, Lifecycle-Management.
Entscheidend ist, die Messbarkeit von Beginn an mitzudenken. Messung von Referenzwerten vor dem Rollout macht Effekte sichtbar. Nutzen Sie begrenzte Inhalte, aber vollständige Kette: vom Datenanschluss bis zur Antwort im Arbeitsfluss. So zeigen Sie, dass die Lösung trägt, und vermeiden Debatten über Tools. Erst danach lohnt es, weitere Quellen und Anwendungsfälle schrittweise zu integrieren.
Wirkung messen, Risiken steuern, nachhaltig verankern
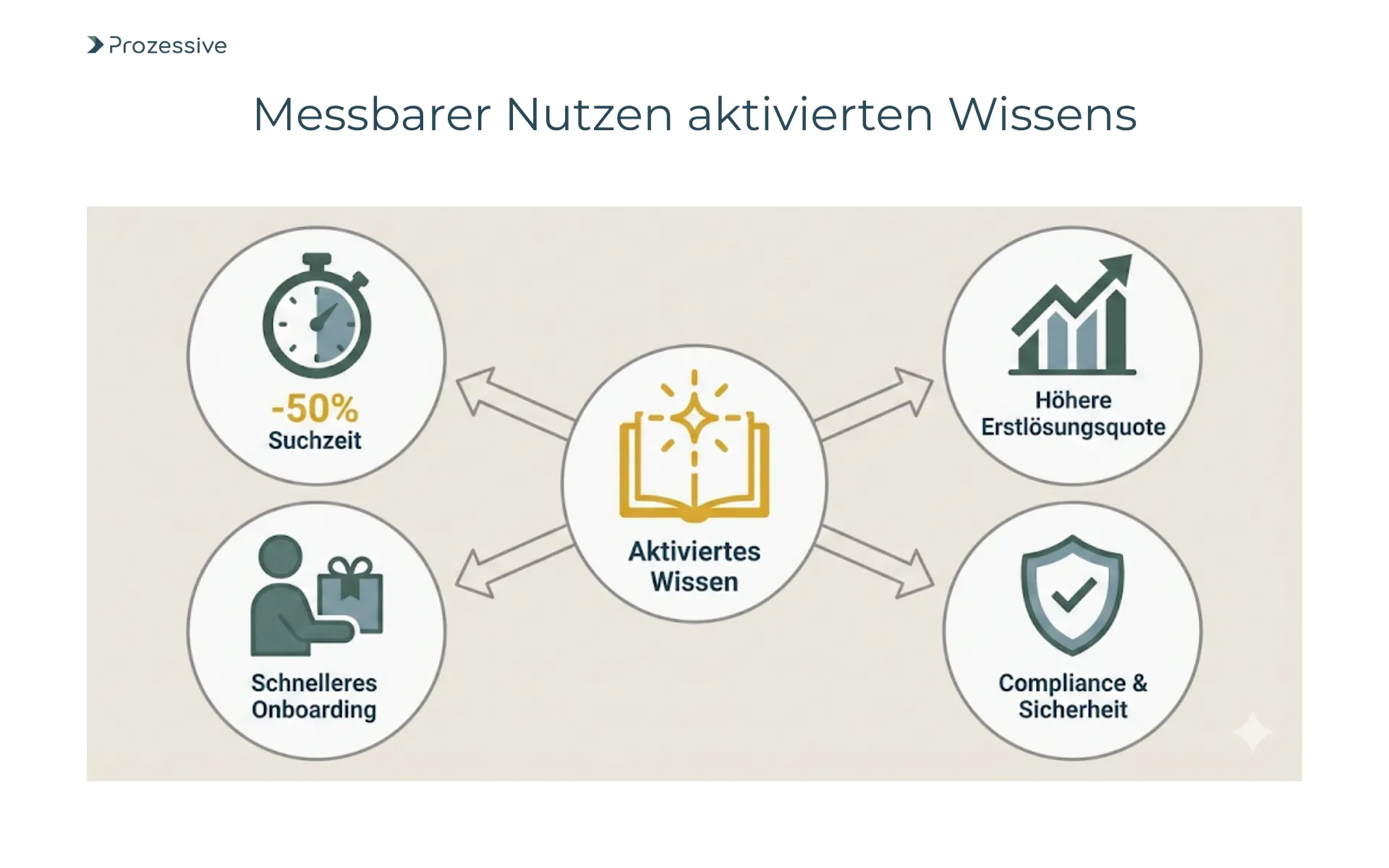
Ohne Wirkungsmessung bleibt jede Initiative angreifbar. Starten Sie mit wenigen Kennzahlen, die nah an der Arbeit liegen. Beispiele sind die Reduktion der Suchzeit pro Fall, die Erstlösungsquote im Service, die Durchlaufzeit im Onboarding sowie die Ticket-Durchlaufzeit für fachliche Rückfragen. Ergänzend lohnt eine Zufriedenheitsbefragung und die Erfassung von manuellen Rückfragen pro Woche. Für eine strukturierte Vorgehensweise hilft die systematische KPI-Messung. Wichtig ist, vor dem Pilot eine Ausgangsbasis zu erfassen, um Veränderungen belegen zu können.
Inhaltliche Risiken sind beherrschbar, wenn Antworten mit Nachweisen versehen werden. Implementieren Sie eine Anzeige der verwendeten Quellenpassagen, sichtbar für interne Nutzer. Ergänzen Sie Feedbackfunktionen für Relevanz und Korrekturen, und etablieren Sie einen Review-Prozess für kritische Inhalte. Annahme: Mit RAG, Quellenanzeige und Relevanz-Feedback sinken Korrekturen deutlich, die Restquote an Korrekturen bleibt aber fallabhängig.
Sicherheits- und Datenschutzfragen lassen sich mit klaren technischen Leitplanken adressieren. Setzen Sie auf rollenbasierte Zugriffe, Least Privilege, Protokollierung und nachvollziehbare Löschkonzepte. Prüfen Sie Datenflüsse aus Sicht von Datenschutz und Betriebsgeheimnissen. Stellen Sie sicher, dass die verwendeten Modelle nur mit freigegebenen Inhalten arbeiten und keine sensiblen Daten außerhalb kontrollierter Umgebungen gelangen. Ein knapper, dokumentierter Freigabeprozess für neue Datenquellen verhindert Schleichwuchs.
Dauerhafte Wirkung entsteht, wenn Technik, Governance und Befähigung zusammenspielen, und wenn Verantwortlichkeiten für Daten, Modelle und Betrieb eindeutig geregelt sind.
Verankerung gelingt über Befähigung und Change. Kurze Trainings, klare Beispiele und Guidelines für Fragestellungen heben die Nutzung. Veröffentlichen Sie Best Practices und typische Suchfragen, etwa aus Service oder HR. Achten Sie bei der Integration in tägliche Arbeit auf niedrige Reibung: Antworten direkt im Ticket, im Intranet-Artikel oder in der Wissenskarte im CRM. Je weniger Kontextwechsel, desto höher die Akzeptanz und desto stabiler die Effekte in der Automatisierung.
Fazit
Wissen verfügbar zu machen ist eine notwendige Grundlage für belastbare Prozessautomatisierung. Die Hürde liegt weniger in der Technik als in Struktur, Berechtigungen und Verantworung. Mit semantischer Suche, RAG und klarer Governance lassen sich Suchzeiten senken, Entscheidungen absichern und Onboarding beschleunigen. Der Weg beginnt klein: eine Datenstrategie light, ein fokussierter Use Case, ein klarer Messplan. Aus einem erfolgreichen Pilot entwickeln Sie Schritt für Schritt ein unternehmensweites Vorgehen.
Wählen Sie zwei kritische Prozesse, definieren Sie drei KPIs, starten Sie einen 6-8-Wochen-Pilot und entscheiden Sie dann datenbasiert über Skalierung. Nutzen Sie Künstliche Intelligenz gezielt, verbinden Sie sie mit Retrieval-Augmented Generation und integrieren Sie Antworten in die Arbeit. So wird aus verteilten Dokumenten ein verlässlicher Wissenszugang - sicher, nachvollziehbar und messbar wirksam.



